
The DNSA’s Kissinger Collection comprises 15,502 telephone conversation transcripts (telcons) and 2163 meeting memoranda transcripts (memcons).

Following declassification, these documents were gathered up by the DNSA, analyzed and curated, and hosted on their online site along with a page of metadata for each document. This data was scraped and converted into a table with a document for each row, and a column for every available metadata property.

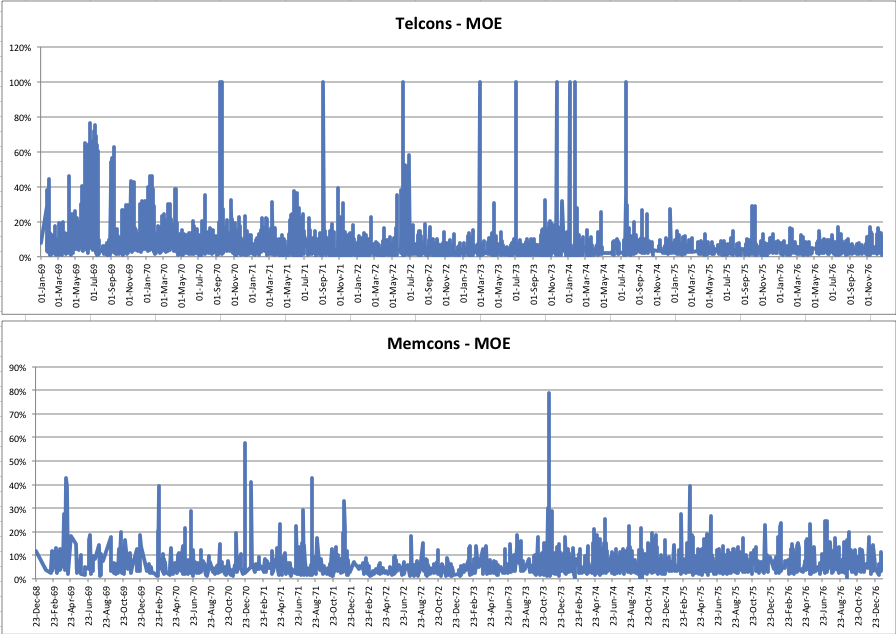
Now, with the metadata cleaned and organized, the documents were put thru Optical Character Recognition, which resulted in (roughly) a 6% margin of error when put through a limited spell check. These OCR results are interesting for a number of reasons, the spikes corrleating to documents where there were no correctly-spelled words because the documents were replaced with handwritten withdrawal slips, an unintended finding aid. It’s also important to note that if a document’s OCR process resulted in it recognizing a word as another, correctly spelled word (eg ‘see’ / ‘sea’) that would not count as an error in this calculation.
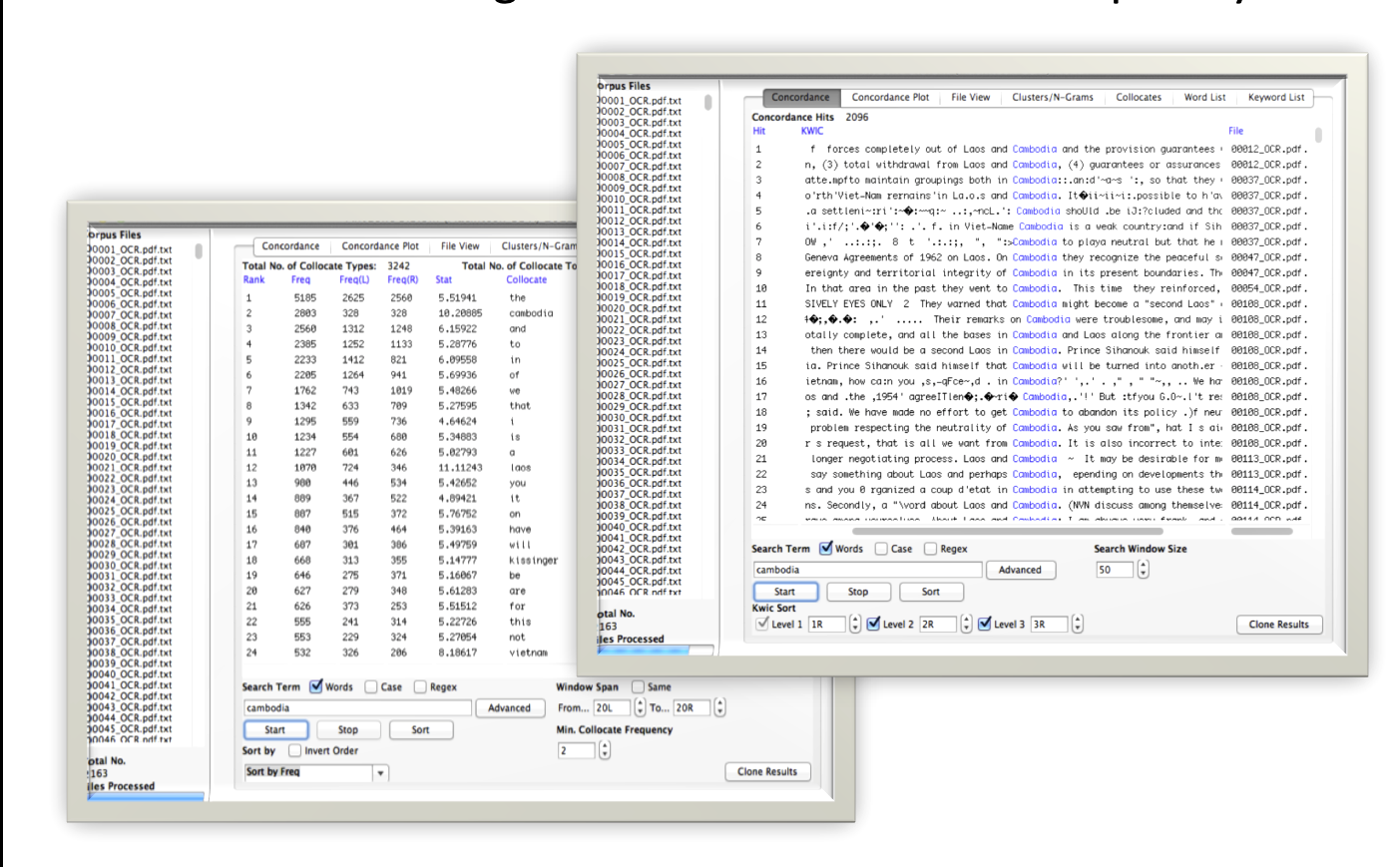
The resulting text files (spell checked but not corrected) were then processed using a number of tools. For Word Frequency and Collocation we used AntConc:
for Topic Modeling we used MALLET, and for Sentiment Analysis we used LIWC2007.